HubDB is a powerful tool and becomes easier to use as we learn to better organize our information. One way of bucketing our data to expedite edits and additions is by creating separate tables for reusable data. If all of our information is in separate tables how would we be able to use all that data together though? That’s where Foreign IDs come in.
Foreign IDs in HubDB
In Hubspot a Foreign ID column type is how we create relational databases. In other words, we’re connecting one table to another. If you’ve worked with other database platforms before, it’s similar to how Foreign Keys work. The column we choose later to identify the different rows in our connected table will function as the Primary Key, our unique identifier.
So, first things first is you would need to have created at least two tables. In our example we’ll have an Events table and an Events – Presenters table. When we connect the two we’ll be able to reuse our presenters for multiple events and also be able to update their information programmatically. This way we won’t have to go through each of our events to update the presenter information multiple times.
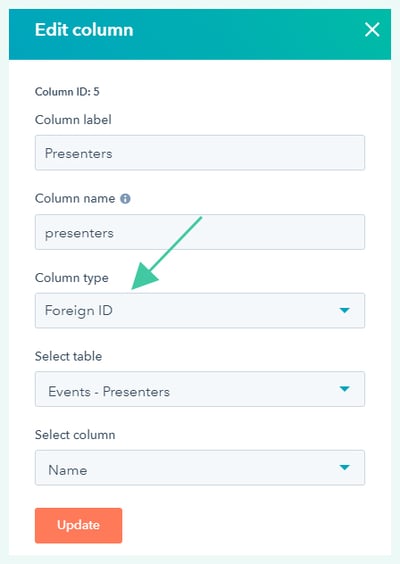
In our Events table we’ll add a column called Presenters. For Column Type we will select Foreign ID. This will make two options available for us, one to choose a table to connect to and the other to choose a column from said table to use as the unique row identifier. We’ll select our Events – Presenters table as our Foreign ID and the Name column as our identifier.
With our Events – Presenters table connected to this column we’ll be able to see a drop down multi-select list of the Name column values. Selecting one will associate that data with the row. Being a multi-select list we can add more than one of our presenters to an event. So not only does having a separate table for our presenters help with editing, but it keeps us from cluttering up our events table with a multitude of columns for adding multiple speakers.
Foreign IDs in HubL
Now we get to the part of how do we output the foreign ID table’s information when outputting our primary table’s information?
We’ll start by using the hudb_table_rows function to grab our primary table’s data. First we’ll set the data to a variable called table (but we can name this variable whatever we would like). The table’s ID will need to be set in the function to know which table’s data to grab. This ID can either be found at the end of the URL to our table or in the ID column on the HubDB dashboard.
https://app.hubspot.com/hubdb/XXXXX/table/1043179
Then we’ll run the data through a for loop to output our events. The column name will be used to tell the loop which column information to output. Note that column name is different from column label. For now we’ll just output the event name.
Now to output our foreign ID table’s information all we need to do is add another for loop inside of our first one. This for loop will loop through our selected values in our foreign ID Presenters column. Then we can grab the data from the rows in our Events – Presenters table that those values are associated with similar to how we outputted the data for our primary table.

We’ve successfully printed both our primary table and our foreign ID table data to the page! From here we can add as many tables and foreign ID columns as we think necessary. In this example we could add an Events – Locations table and a Locations foreign ID since a lot of our events are likely to take place in the same locations. Just don’t go too hog-wild in separating out the data. When deciding on what data to create separate tables for we can ask ourselves the following questions:
- Is this data going to be used throughout multiple rows?
- Is this separate table going to have more than one column of information?
- Will a row need to include more than one of this type of dataset?
As long as it’s used wisely relational databases in Hubspot using Foreign IDs helps keep our data manageable, scalable, and easier to update. So it’s a good feature to keep in mind when using HubDB and/or when a huge chunk of data falls into our laps.